Database Replication
একই ডেটা একাধিক সার্ভারে - HA ও read scaling-এর ভিত্তি।
আপনার একটি গুরুত্বপূর্ণ document শুধু একটি ল্যাপটপে আছে - চুরি গেলে, hard drive crash করলে কী হবে? নিরাপত্তার জন্য Google Drive-এ copy রাখেন। সেটাই Replication - একই ডেটা একাধিক জায়গায়।
Replication কী?
Database Replication = একই data একাধিক DB instance-এ রাখা। সাধারণত একটি primary (master) write নেয়, তা replica (slave)-গুলোতে copy হয়।
কেন Replication?
- High Availability: Master fail করলে replica নিতে পারে।
- Read scaling: Read replica-গুলোর মধ্যে query distribute।
- Backup: Replica-ই backup-এর কাজ করতে পারে।
- Disaster Recovery: Geographic replica - region down হলে।
- Reduced latency: Geographic replica user-এর কাছাকাছি।
- Maintenance: Master maintain করার সময় replica serve।
Topologies
১. Master-Slave (Primary-Replica)
একটি master, এক বা একাধিক replica। সব write master-এ; replica-তে copy হয়।
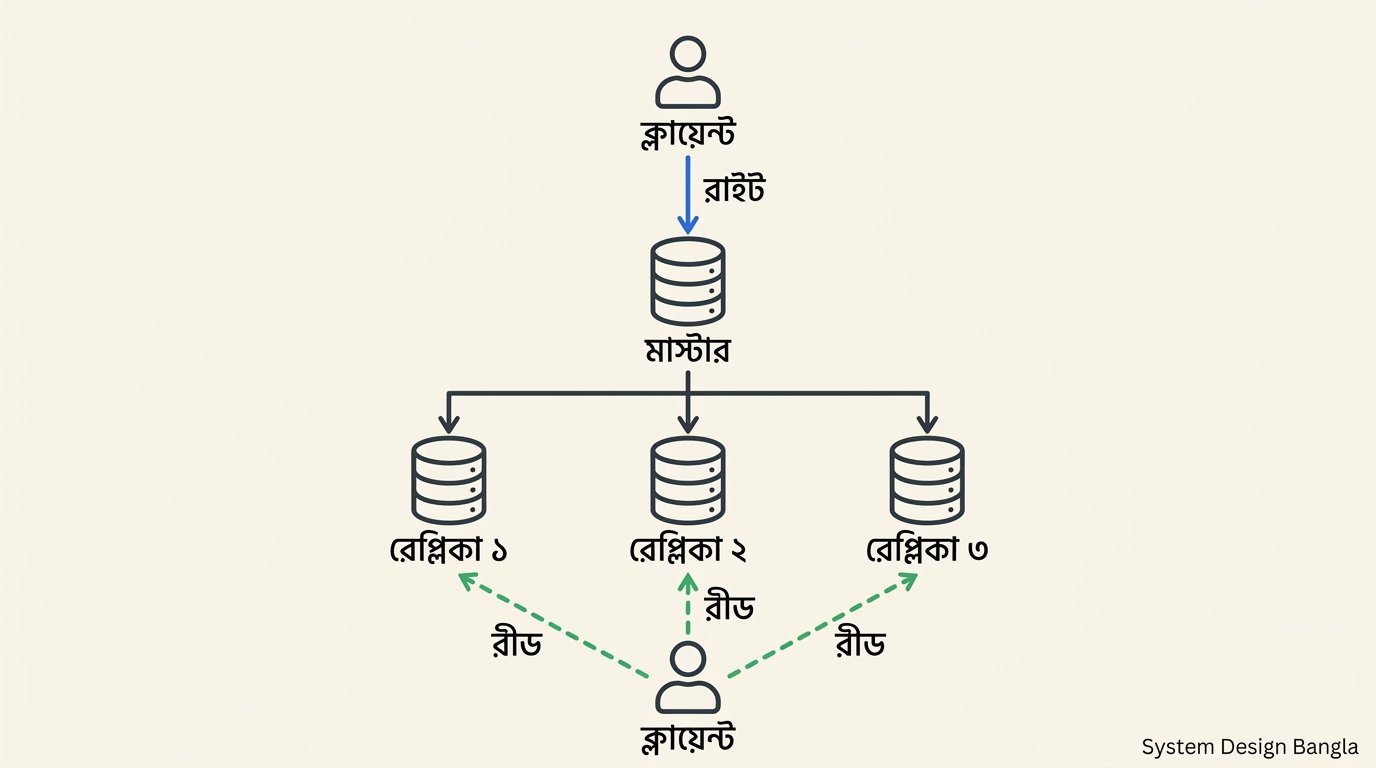
- সুবিধা: সরল, write conflict নেই।
- অসুবিধা: Master single point of failure (write-এর জন্য)।
২. Master-Master (Multi-master)
একাধিক master - সবাই write নিতে পারে। একে অপরকে replicate করে।
- সুবিধা: Write availability - এক fail হলেও অন্য চলে।
- অসুবিধা: Write conflict - দুই node একই row-এ লিখলে।
- Conflict resolution: Last-write-wins, vector clock, CRDT।
৩. Cascading Replication
Replica নিজেই অন্য replica-কে data forward করে - chain পদ্ধতি।
৪. Circular Replication
A → B → C → A - কম common, complex।
Synchronous vs Asynchronous
Synchronous Replication
- Master write replicate হওয়া পর্যন্ত wait
- Replica-তে data পৌঁছানো নিশ্চিত
- Strong consistency
- ধীর - network latency-এর উপর depend
- Banking/financial-এ ব্যবহার
Asynchronous Replication
- Master commit-এর পর replicate
- দ্রুত write
- Replication lag থাকে
- Master crash → কিছু data lost সম্ভব
- সবচেয়ে কমন
Semi-synchronous
Hybrid - কমপক্ষে একটি replica acknowledge হলেই commit, বাকিরা async। MySQL-এর popular option।
Replication Lag
Replication lag = master-এ write হওয়ার পর replica-তে পৌঁছানোর সময়। সাধারণত ms-second। কিন্তু network slow হলে minute হতে পারে।
সমাধান
- Sticky session: User-এর own write-এর পর master থেকে read।
- Wait for replica: Sync replication critical part-এ।
- Read from master: Critical-after-write read।
Replication Methods
Statement-based
SQL statement (UPDATE...) replica-তে পাঠানো। Compact কিন্তু non-deterministic function (NOW(), RAND()) সমস্যা।
Row-based
প্রতিটি changed row replica-তে। Larger but accurate।
Mixed
MySQL default - case অনুযায়ী switch।
Logical Replication
Logical change (insert row X) - version-different DB-এ replicate possible।
Automatic Failover
Master fail হলে replica-কে promote করা - automate করতে হবে:
- Health check: Master-কে periodically ping।
- Election: কোন replica master হবে - sync status দেখে।
- Promotion: Selected replica-কে read-write mode।
- Reconfigure clients: নতুন master-এ point।
Tools: MHA, Orchestrator, Patroni (Postgres), AWS RDS auto-failover।
বাস্তব উদাহরণ
- Facebook: MySQL master + অনেক read replica (region-wise)।
- YouTube: Vitess (MySQL + replication + sharding) - Google open-sourced।
- GitHub: MySQL multi-region replication (Orchestrator-এ failover)।
- AWS RDS: Multi-AZ standby - sync replication + auto failover।
সাধারণ ভুল ধারণা
- "Replication = backup": না - replication প্রতিটি change copy করে। Accidental DELETE replica-তেও যাবে।
- "Async replication-এ data lost হয় না": Master crash হলে un-replicated transaction lost।
- "Multi-master = সবসময় better": Conflict resolution complex; অনেক ক্ষেত্রে master-slave সরল ও যথেষ্ট।
Best Practices
- Replication monitor - lag, fail track।
- Read-your-writes consistency-র দরকার থাকলে master থেকে read।
- Critical write-এ semi-sync বা sync replication।
- Backup আলাদা - replication-এর সাথে ভিন্ন।
- Test failover drill - production-এ surprise নয়।
- Geographic replica DR ও latency-র জন্য।
📌 চ্যাপ্টার সারমর্ম
- Replication = একই data একাধিক জায়গায়।
- Master-slave সরল; multi-master complex।
- Sync = strong consistency কিন্তু slow; Async = fast কিন্তু lag।
- Replication lag → "read-your-writes" সমস্যা।
- Replication backup-এর বিকল্প না।